Introducing Luft - Airbridge’s in-house OLAP Database

As a mobile attribution solution, Airbridge processes over 10 billion records of data every month to provide analytics for campaign performance, user behavior, and growth metrics across the web and app. Analyzing user behavior in real-time is crucial for campaign optimizations.
Airbridge developed an OLAP database that focuses on user behavior to provide real-time analytics. Let’s take a closer look at how Luft works to offer cohort analysis and real-time reports.
How Cohort Analysis Works
Cohort analysis aims to analyze the behavior of a group of users. For example, calculating the retention rate of ‘female users in their 30s who spent more than $100 in the last six months’ is an example of cohort analysis.

It is a two-step process: first, define a specific user group, then load the event data of users who belong to the group and analyze their behaviors. However, the time it takes to process the data for these steps is an issue. Results could be sent via email once the analytics are done, but it would make it virtually impossible for data analysts to test the results in real-time with a UX environment. Hence, the need for performance that can process instant analytics on the Airbridge dashboard.
Limitations of Conventional Architectures
Airbridge has been using Apache Druid to analyze data. Druid is an OLAP data store that can process analytics queries within a few seconds, through pre-aggregating set metrics periodically and roll-up methods that select then calculate specific values upon query.
Most OLAP databases, including Druid, pre-aggregates set metrics that were precalculated. Since it reads readily available data rather than raw data, queries can be quickly processed. However,
- Druid cannot query metrics that are not pre-computed. So in order to perform a different type of analysis, data has to be newly indexed.
- Advanced behavioral analysis, such as funnel analysis, cannot be done without raw data.
While Druid was an optimal solution for various Airbridge reports in the past, limitations became apparent when real-time cohort analysis was being developed. The fact that the necessary queries can't be immediately processed and the low performance (minimum 15 seconds when testing queries) was an issue.
Shuffling keys with high-cardinality deteriorates performance
Queries analyzing user behavior involve grouping event data by user ID. Generally, MapReduce frameworks go through a shuffling phase when running Groupby queries. Once data is sorted by key and partitioned, data is sent through the network.
The shuffling phase is a bottleneck because user ID is a key that has very high cardinality. For example, if a client with more than millions of daily users opens a report, millions of user IDs have to be sent through the network - significantly deteriorating performance for most solutions.
Why we had to develop Luft ourselves
After testing existing solutions, we came to the conclusion that we would have to develop a new in-house solution tailored to our needs.
- Cost Efficiency: Data warehouses such as Snowflake or Redshift could cover our analytics and performance needs, if scaled to large proportions.However, commercial data warehouses are all-purpose databases that are not optimized for OLAP, and we would have to operate clusters much bigger than what we wanted. We believed that there was room for a lot of optimization considering the characteristics of OLAP queries and data for user behavior analysis, and decided to reduce cluster costs by developing an in-house solution.
- Varying Queries: There were limitations when using an SQL database for not only trend reports and retention reports that we were already providing, but also for other varying features such as funnel analysis or identity matching. Data processing engines (e.g. Spark) were used for certain analyses, but these solutions also had performance and cost efficiency issues. The need for a custom in-house solution was apparent.
Luft: Datastore designed for user behavior analysis
To solve the issues outlined above, Luft was designed as a data store that could quickly process user behavior queries grouped by user ID. Airbridge is currently performing cohort analysis on tens of terabytes of user data using less than five nodes and within 3-10 seconds on average.
Unlike most RDBMSs, Luft’s data are immutable. OLAP datastores are mostly used to analyze event data of a user’s behavior. Since the event data does not change once stored, many datastores do not let you edit data that are already ingested. Instead, they can be overwritten by importing new data from the same time period.
Thanks to these immutable properties, we were able to overcome many challenges that were met by DBMSs. Instead of using complex cluster structures for various data consistency issues, we could adopt simple clusters like Druid. Also, we could rely on pagecache for data caching like Kafka does and achieve higher performance without the need of a page manager.
However, the most significant advantage is that we could design the data storage formats necessary for Airbridge.
Storage Engine
RDBMS uses a binary tree or skip-list data structure because its data should be modifiable. However, as Luft’s data are immutable, we were able to optimize data structures for user behavior analysis to greatly improve its performance. We chose to use Adroll’s TrailDB as Luft’s storage engine.
TrailDB is designed to store user events with a rowstore. User data is stored after it has been grouped by users and sorted by time, and TrailDB provides various encoding methods to support these data properties.
- Delta Encoding: As events are sorted by event timestamps, event timestamp information is stored as time differences between data.
- Dictionary Encoding: Rather than storing complete data values, it catalogs data into a dictionary and stores only their IDs.
- Edge Encoding: As user information like age, e-mail, and device type rarely changes for behavioral data, only changed columns are stored to prevent unnecessary storage actions.
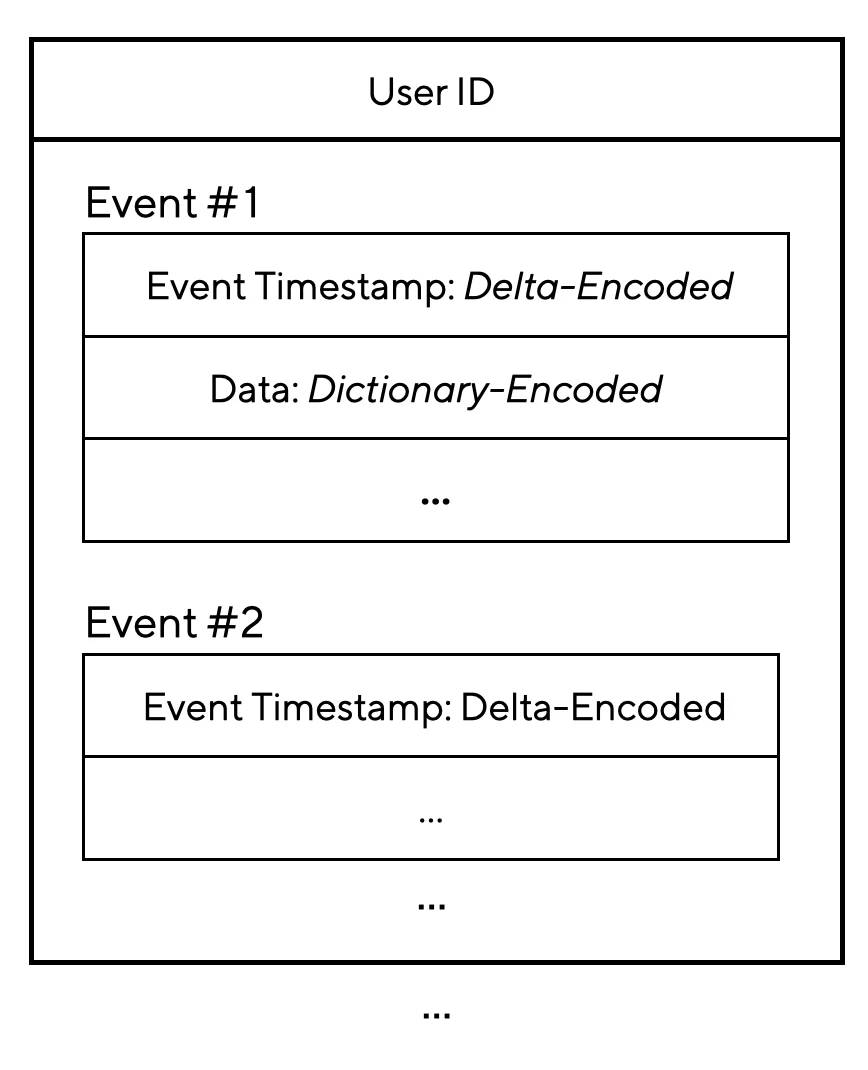
Such data structure enabled us to compress our user data by a surprising 97% while maintaining decoding performance with the same time complexity. In practice, 13GB of sample data exported from Airbridge in CSV format was compressed to 300MB after it was encoded by TrailDB. Smaller data means more data can be cached in RAM.
Performance deterioration issues that occur during the shuffling phase were also resolved with the data being already partitioned by the user at the storing phase. It is much easier to shuffle pre-grouped users than shuffling each event separately. Moreover, since the offset of each data is recorded, it is possible to read the necessary user data only. This means that the amount of data that has to be read in order to perform cohort analysis decreases greatly.
You only scan once
A query that analyzes user behavior usually consists of multiple subqueries. In order to save scan time, Luft was designed to scan all the necessary data in one go.
Airbridge’s user events are temporal data, and every query contains a time period. Therefore depending on the event timestamp, Luft partitions data into temporal blocks. If the time period of subqueries overlap with each other, a redundant scan for the same time period will happen.
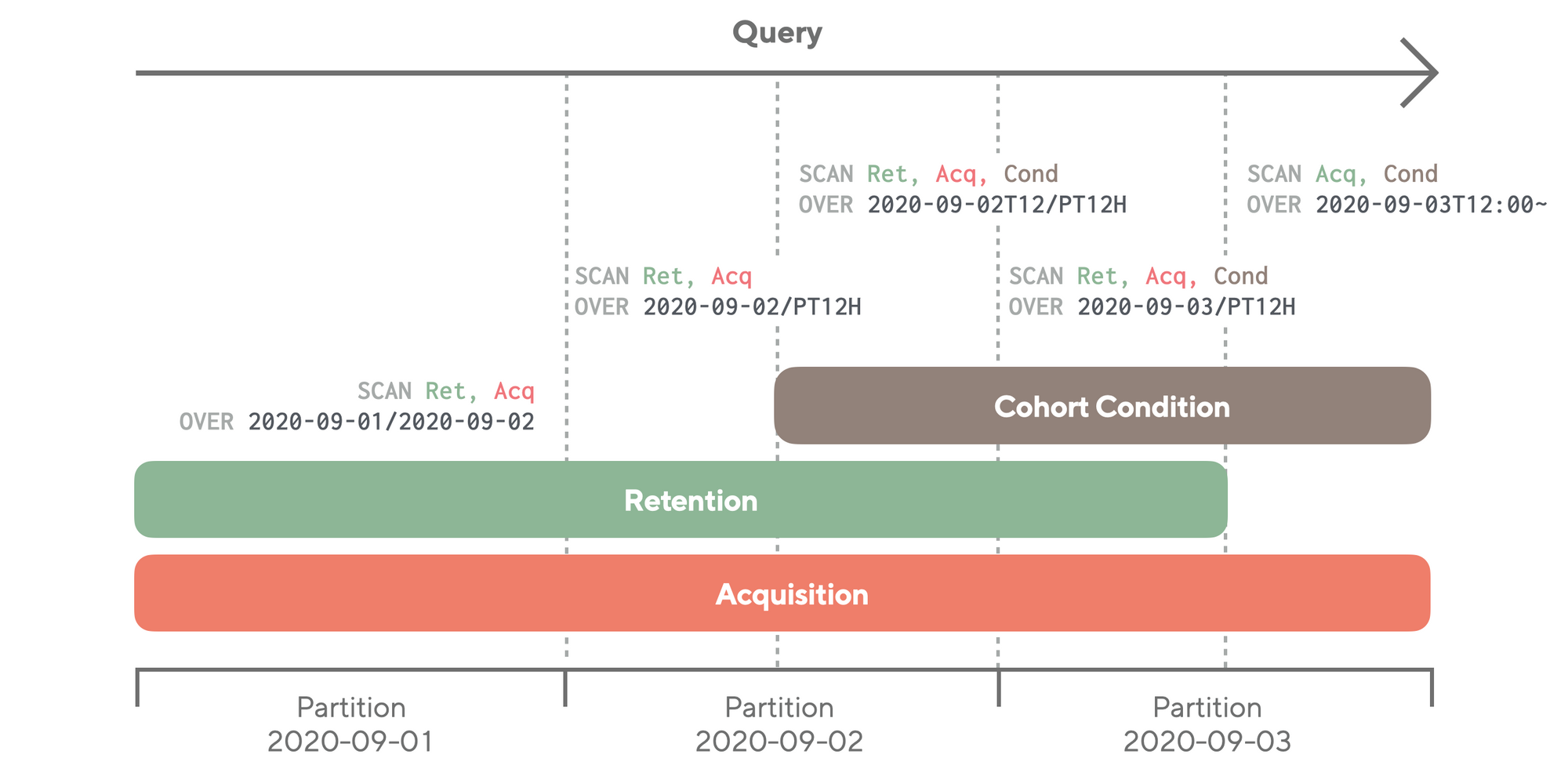
A query is optimized by Luft during the query planning phase so that only a single scan is needed. Various subqueries are optimized by being split along the time axis and merged if the queries are similar. Since the results from the query are merged, queries can be quickly processed through a single scan without redundancy.
Architecture for Consistency
We also adopted Lambda Architecture for real-time queries. Lambda Architecture is a data-processing architecture that uses both batch and stream-processing methods. The data pipeline is separated into batch layers and real-time speed layers. Data is then processed after the pipeline is merged at the actual serving layer. Lambda architecture assures eventual consistency as the integrity and consistency of real-time data is secured by overwriting batch data.
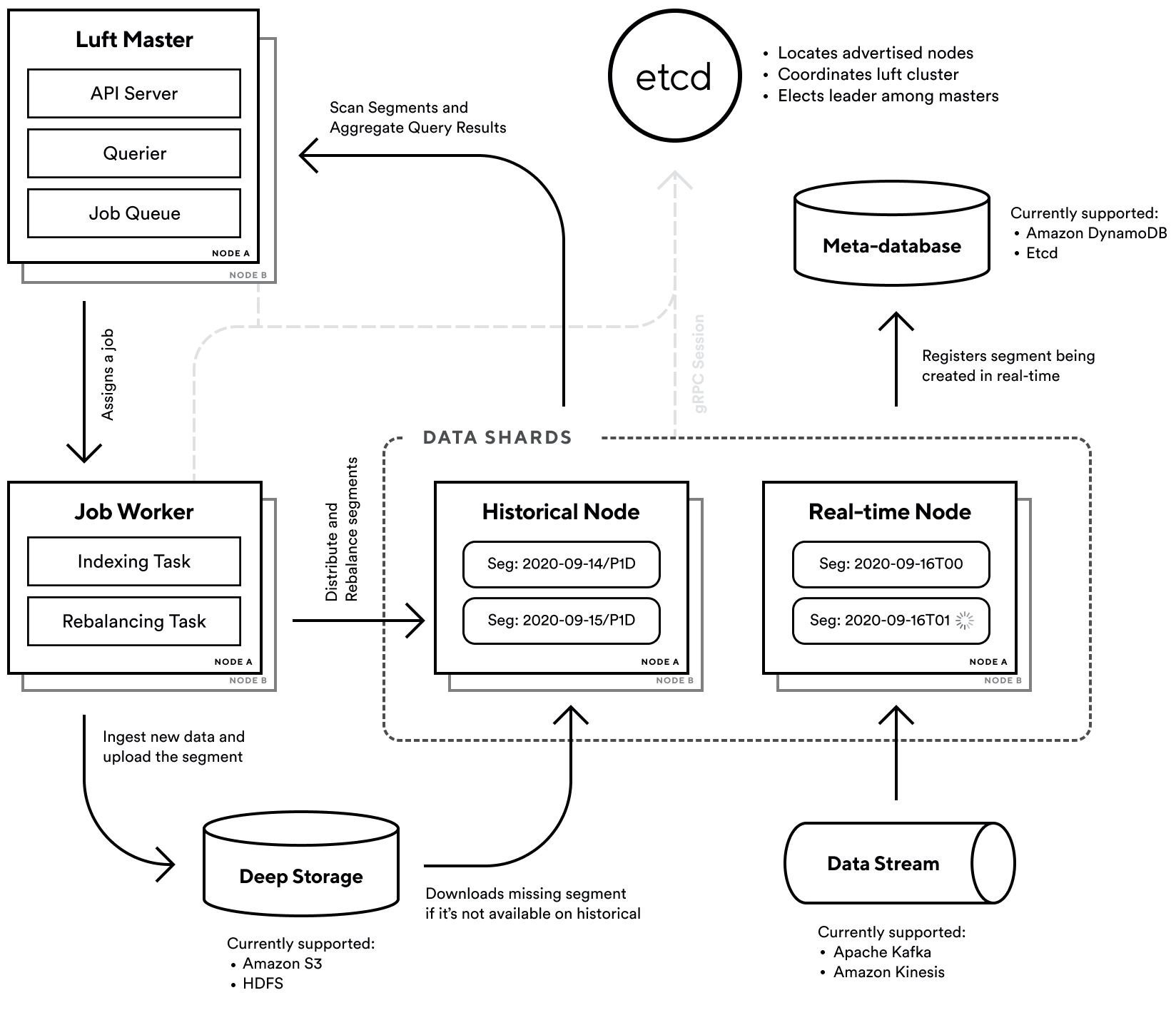
Luft adopted Druid’s structure that utilizes Lambda Architecture, and defined the nodes’ roles as below:
- Real-time nodes: Data shards that reads and stores real-time data from data streams such as Kafka
- Historical nodes: Data shards that store batch data. It caches batch data and executes queries.
Even with the architecture above, each node has a possibility of data loss or data between nodes might not be consistent. To prevent this, data is stored in S3 by default, and only necessary data is stored in the nodes’ disk or memory.
If the data for a query is not stored in a node, it may take some time to download it from S3. We protect against cache miss by using methods such as storing recent data that are more likely to be queried in the nodes and use Linux’s user-space page fault handler to download data from S3 quickly.
More Insights From Existing Solutions
We gained many insights from existing advanced solutions.
- We referred to Spark and Kafka to develop a MapReduce layer using Golang and gRPC. We were able to execute online queries with outstanding performance using partition scheduling methods and a pull-based stream structure.
- We designed clusters using etcd. Zookeeper is widely used, but etcd had lower management costs and restrictions, while also being highly proven through projects like Kubernetes.
- We make the most of cloud storage. We were able to cut cluster costs effectively by storing data in S3, using DynamoDB for managing metadata, and managing Kubernetes workload scaling ourselves.
Conclusion
Our goal is to perform real-time user behavior analysis on terabytes of data with small-to-medium-size clusters. Luft’s short term goal is to perform funnel analysis on tens of terabytes of user data with less than 40 CPU cores. We are focusing on optimizing performance and improving data structure to reach this goal.
We will continue to upgrade Airbridge’s features using Luft.
Ready to transform your mobile growth?
Learn how Airbridge helps leading brands measure and optimize every touchpoint.


